Is SEO Dead in 2026? Analyzed 370,000+ Search Results behind ChatGPT and Gemini Prompts to Find Out.

- TL;DR
- The Study
- The Hidden Search Pipeline: Fan-Out Queries
- How a ChatGPT Response Is Structured
- The Oldest SEO Trick That Also Works for GEO: Year Injection
- Why Localization Matters for GEO: Cross-Language Fan-Outs
- Which Search Engine Do LLM Citations Come From?
- Is ChatGPT Scraping Google Search Results?
- How Much Does Search Rank Decide Whether You Get Cited?
- What ref_index Reveals: the Rank ChatGPT Actually Saw (GPT-5.5)
- The Ground-Truth Rank Distribution, From ref_index
- The Citations That Bypass Search: Labrador
- What Type of Content Gets Cited?
- Should You Put Your Own Product at #1 in a Listicle?
- Does Structured Content Like Tables or Bullet Points Help You Get Cited?
- If an LLM Cites You, Does It Get the Details Right?
- Your GEO Strategy Depends on Which ChatGPT Tier Your Customers Are On
- How I Collected the Search Data
- So Is SEO Dead?
- Frequently Asked Questions
As someone who’s been deeply involved with SEO for our brand, I’ve also been paying attention to how GEO (Generative Engine Optimization, or whatever name you prefer) is shaping up. I’ve been reading casually in the space, and one claim I kept running into was that SEO is dead. I wanted to know if that actually holds.
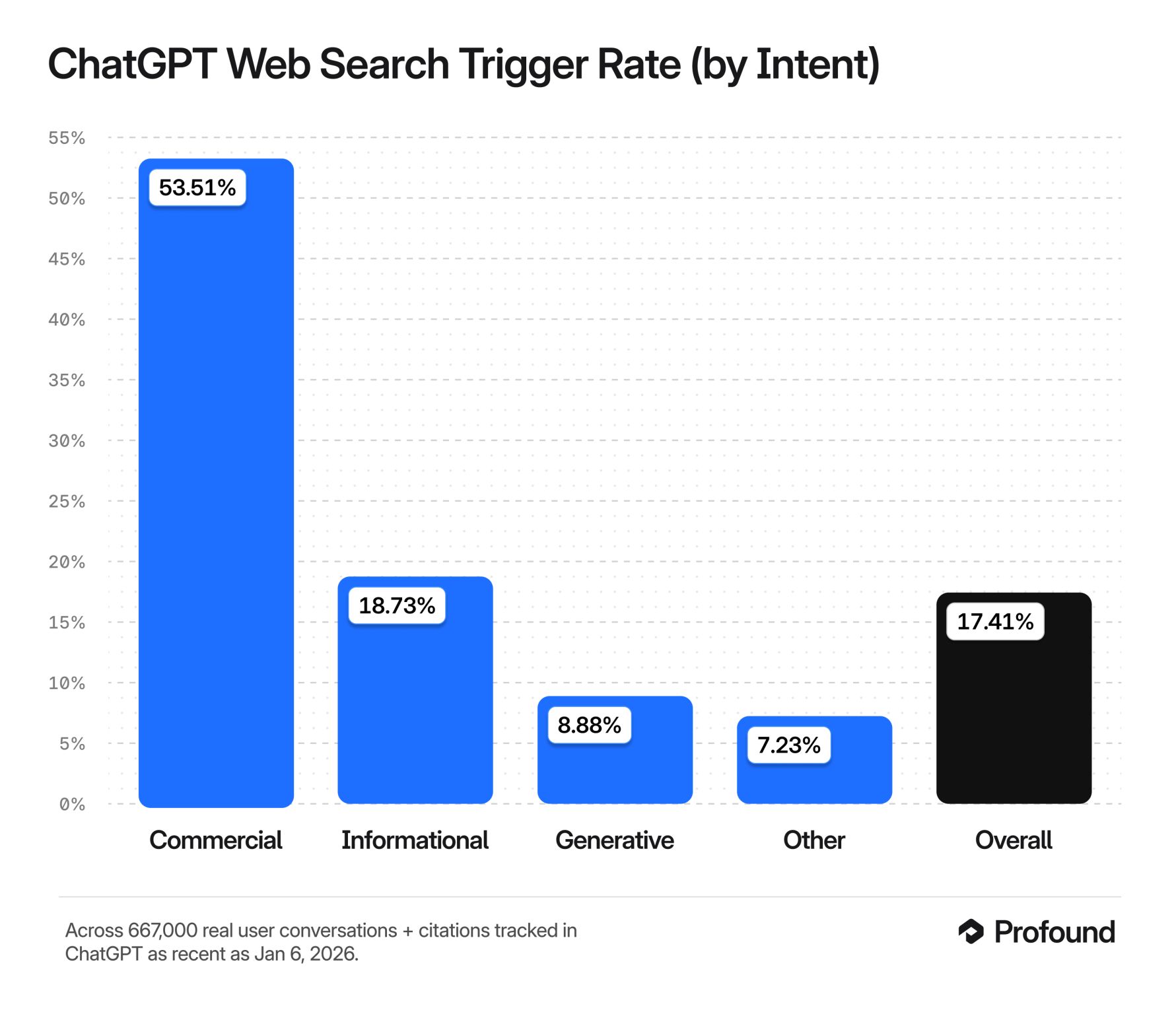
It isn’t an abstract question for us. At Maestra we build AI translation and transcription tools, exactly the kind of products people now ask large language models like ChatGPT and Gemini to recommend. And these are the prompts that make LLMs search the web in the first place: in Profound’s analysis of 667,000 real ChatGPT conversations, commercial prompts triggered a web search 53.5% of the time, which is why we took a closer look at them.
So I made it my master’s thesis at TUM (Technical University of Munich): how LLMs use web search when they recommend products, scoped to a domain I know well, AI speech technologies. 79 prompts, 3 runs each (for cross-run variance), across ChatGPT Plus, ChatGPT Business, and Gemini. Around 1,650 runs over three model generations, 370,000+ search results captured, and 13,000+ citations analyzed.
TL;DR
- ~80% of AI product recommendations trace directly back to search rankings.
- ChatGPT Business reads Bing; ChatGPT Plus reads Google (scraped via Bright Data). On GPT-5.5, every citation carries its provider (result_source) and the exact rank it was returned at (ref_index).
- On GPT Business/Bing, 94% of citations come from the top 10; GPT Plus (Google) cited from deeper results, down into the low 20s.
- ~12–15% of citations bypass search entirely through an internal channel (“labrador”: Wikipedia, arXiv, major tech press) that SEO can't reach.
- Listicle position decides a lot: the #1 item is picked at 1.7–2.5x chance, and the top 5 take 76–81% of all selections.
- Putting the year in queries became common in ChatGPT, growing from ~5% of runs to ~80% across model versions, and year-tagged “best of 2026” listicles dominate what gets cited.
- Verdict: for SaaS product recommendations, SEO isn't dead. Good SEO is the bare minimum for good GEO.
The Study
I collected data from three AI environments:
- ChatGPT Plus (consumer tier). 237 runs across 79 prompts, run directly through chatgpt.com
- ChatGPT Business (enterprise/education tier). 237 runs across 79 prompts, run directly through chatgpt.com
- Gemini (via Vertex AI API, Gemini 3.0 Flash). 237 runs across 79 prompts
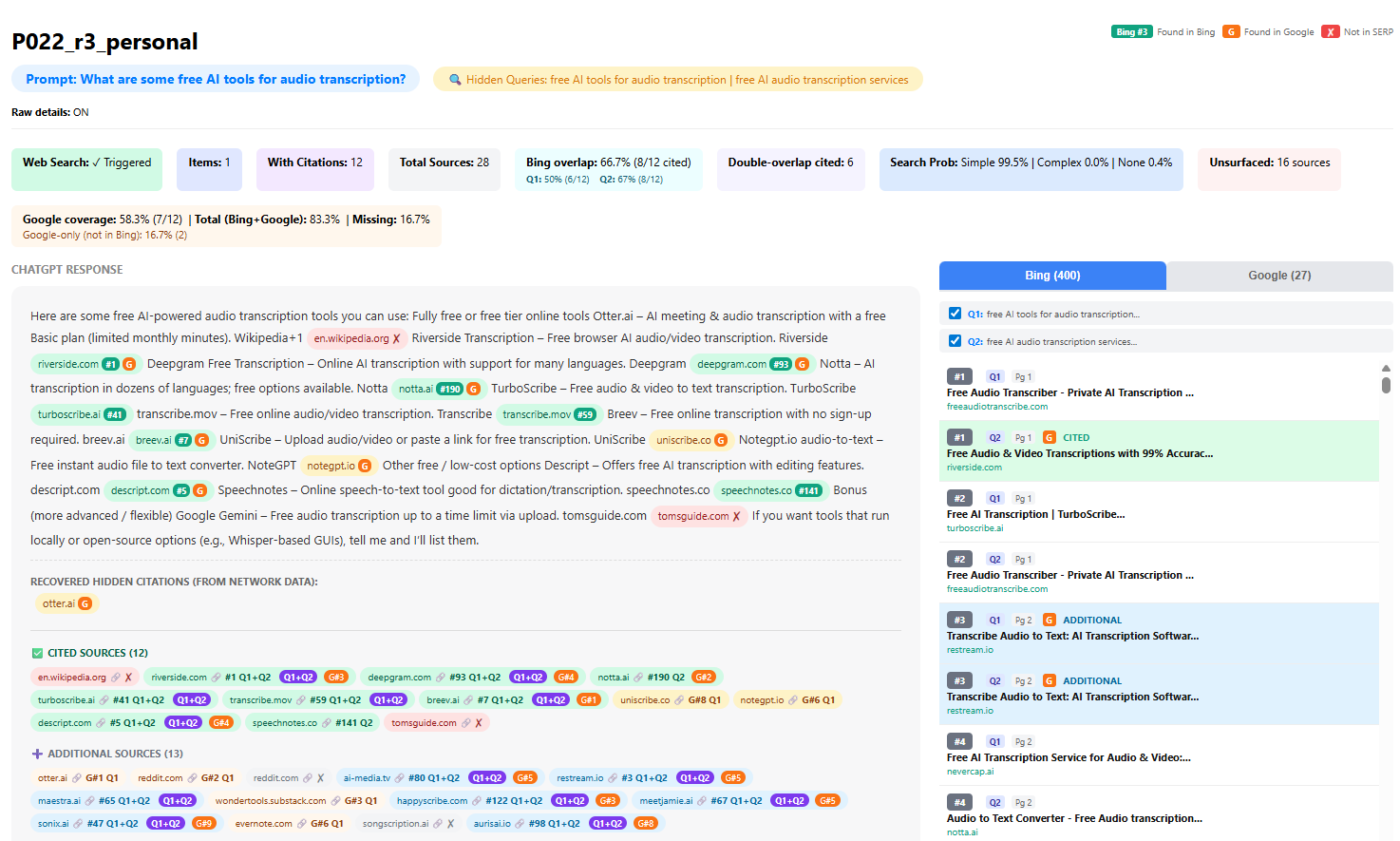
All prompts were commercial product queries in the AI speech and language technology space, transcription, live translation, video dubbing, text-to-speech. I specifically leaned toward prompts I expected to trigger a web search and list products in the responses. I sourced 65 prompts from Profound's Prompt Volumes, which surfaces real anonymized ChatGPT user prompts, and 14 from Ahrefs' AI Citations feature. Some sample prompts were: "What are some free AI tools for audio transcription?" or "Can you recommend a real-time voice translator app?"
📌 Scope note: the study is about commercial, product-recommendation prompts that trigger a web search, the kind where a SaaS tool actually gets named and cited. The findings might not carry over to general-knowledge questions, non-commercial queries, or anything a model answers from its own memory without searching.
That first wave ran on GPT-5.2. I re-ran the same ChatGPT prompts on the next two model generations, since I wanted to see how the responses to the same dataset would change over time:
Wave 1 — GPT-5.2 (January 2026): ChatGPT, both tiers, plus Gemini.
Wave 2 — GPT-5.3 (April 2026): ChatGPT re-run, both tiers.
Wave 3 — GPT-5.5 (May 2026): ChatGPT re-run, both tiers.
For each ChatGPT run, I captured the full response including all cited sources, the hidden fan-out queries used to search the web, and the internal search classifier data, and visualized everything in an interactive data viewer at geo.maestra.ai. For Gemini, I used the official API which exposes structured grounding metadata. I then cross-referenced every citation against Bing and Google search results for the same queries.
The Hidden Search Pipeline: Fan-Out Queries
A quick primer for anyone new to how this works. When you ask ChatGPT a question, you see a brief "Searching the web..." indicator.
But under the hood, LLMs don't send your question to the search engine as-is. They rewrite your prompt into what are called fan-out queries. These rewritten queries determine which search results the model has access to, and by extension, which products it can recommend.
For example, "What are some free AI tools for audio transcription?" becomes:
- Q1: free AI tools for audio transcription
- Q2: best free speech to text transcription tools online
Each of these queries gets run against the search engine, and the pages ChatGPT cites back to you are pulled from those results (most of the time). So before the model picks anything, the fan-out has already decided which pages are even in the running.
Fan-out behavior itself changes across GPT versions. In GPT-5.2 ChatGPT always fired two queries; by GPT-5.3 and GPT-5.5 that dropped to a single combined query.
| Model | Fan-out queries per search |
| ChatGPT 5.2 (Jan 2026) | 2 |
| ChatGPT 5.3 (Apr 2026) | 1 |
| ChatGPT 5.5 (May 2026) | 1 |
| Gemini (Feb 2026) | 3–7 |
In the original GPT-5.2 wave I captured 2,280 fan-out queries across 711 runs — 448 queries from Business, 424 from Plus, and 1,408 from Gemini. ChatGPT's two queries contributed almost equally to the citations. Gemini fires 3–7 per run through its grounding API, though its first query dominated the citations by a wide margin. Gemini also exposes its fan-out queries natively in the API; for ChatGPT I had to pull them out of the network stream.
How a ChatGPT Response Is Structured
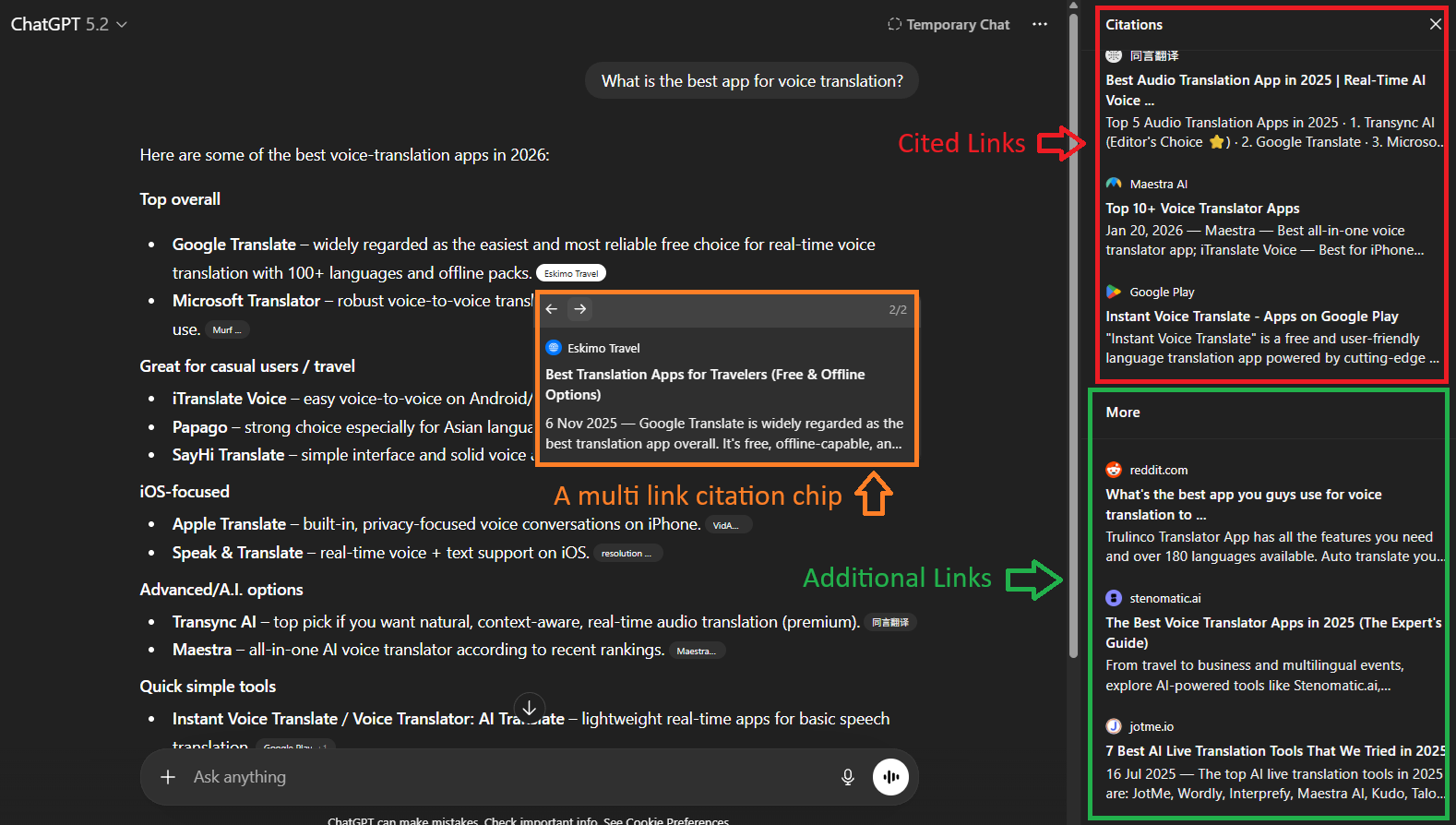
Before the findings, here's how I categorize the URLs in ChatGPT's responses:
- Cited links. The numbered footnotes that appear directly in the response text. These are the primary recommendations the user sees and is most likely to click.
- Additional links. URLs listed in the Sources panel on the right side of the response. ChatGPT retrieved these and considered them relevant, but didn't reference them inline. Think of them as "supplementary reading."
Throughout this study, when I say a page was "cited," I mean it appeared as an inline cited link in the response text.
The Oldest SEO Trick That Also Works for GEO: Year Injection
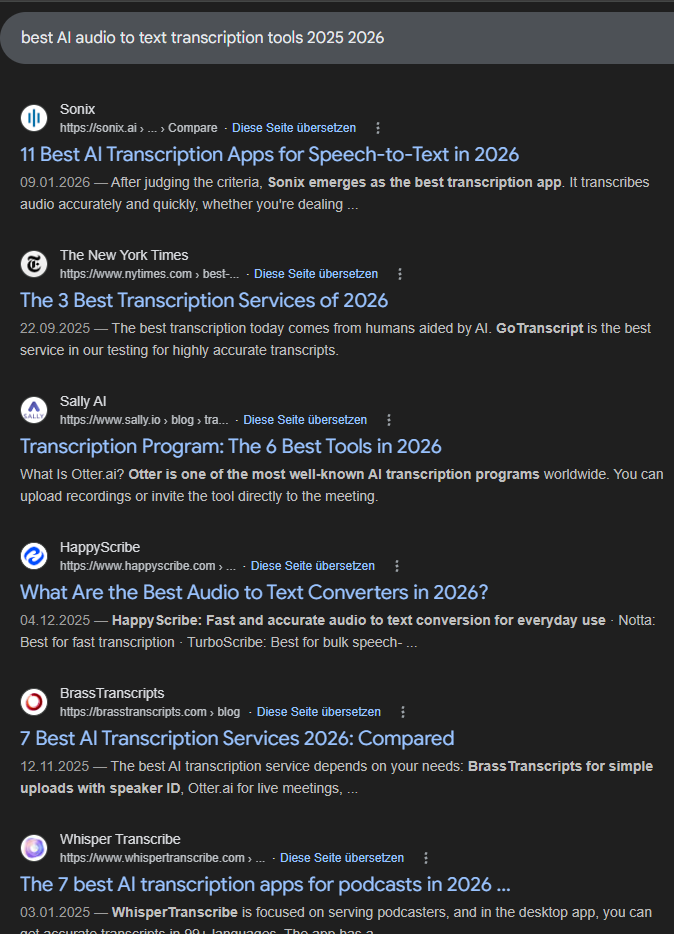
When I ran the January study, Gemini was doing something ChatGPT wasn't at the time: jamming the current year into its fan-out queries. A question about transcription tools became "best AI audio to text transcription tools 2025 2026."
97.8% of Gemini runs included at least one year-injected query, and 68% of all its queries carried a year token. The result is what you see in the screenshot here: a SERP filled almost entirely with year-tagged listicles.
ChatGPT 5.2 barely did this in January, around 5% of runs. But on my runs of the same prompts with GPT-5.3 and 5.5, that changed a lot:
| Version | Business | Plus |
| GPT-5.2 (Jan) | 6% | 5% |
| GPT-5.3 (Apr) | 53% | 60% |
| GPT-5.5 (May) | 87% | 79% |
Counted among runs that actually fired a web search; runs answered from memory aren't included.
So yeah, you can (and should) just update your blog title and meta description with the current year every January and get a visibility boost.
Why Localization Matters for GEO: Cross-Language Fan-Outs
When I was running the prompts back in January on GPT-5.2, I kept getting German cited links even though I was prompting in English. It only made sense once I started looking closely at the fan-out queries.
Peec AI's analysis of 20 million fan-out queries found that 78% of non-English ChatGPT sessions include at least one English-language fan-out query, and 43% of all fan-out queries for non-English prompts target the English web. My data confirms this pattern, and I found two additional cases they didn't document:
Case 1: Foreign prompts get an English companion.
Q1: meilleur logiciel de traduction instantanée traduction en temps réel logiciel
Q2: best real-time translation software instant translation tools comparison
see full run
100% of foreign-language prompts that triggered search showed this. A non-English website is competing against the entire English web for half of its AI visibility.
Gemini showed a similar English-first pattern: for foreign-language prompts, it always reserved the first query slot for an English translation, and the first query consistently dominated the citation results. So even on Gemini, English content gets priority in retrieval.
Q1: best real-time translation software 2025 2026 review
Q2: comparatif logiciels traduction simultanée 2025
Q3: meilleur logiciel traduction instantanée 2025 2026
Q4: meilleure application traduction instantanée voix texte 2025
But I also came across two other cases of cross-language fan-out behavior on ChatGPT:
Case 2: Context-triggered.
Q1: best software for Persian Farsi audio to text transcription Persian speech to text
Q2: بهترین نرم افزار تبدیل گفتار فارسی به متن Persian audio transcription software
see full run
Here the trigger was the prompt itself: just because it mentioned Farsi, one of the fan-outs came back in Farsi (Q2) alongside the English one.
A user's IP address or locale could also trigger this. If you're browsing from Germany, ChatGPT might add a German fan-out even if your prompt is in English.
Case 3: Completely unprompted. 24 runs across 15 English prompts received non-English fan-outs despite zero foreign-language signal in the prompt:
Q1: free website or program to translate video and add subtitles automatically
Q2: 免费工具 翻译视频 字幕 自动 translate video subtitle free online
see full run
You can see the full list of localization cases on the dashboard under Fan-Out Localization Patterns.
On GPT-5.3, with the fan-out down to a single query, ChatGPT picked the English version: French and German prompts got rewritten to English, others stayed native, and it looked like localization was being dropped. On GPT-5.5, it went back to foreign language. Foreign prompts search in their own language: French stays French (“meilleur logiciel de traduction instantanée 2026…”), Chinese stays Chinese (“实时翻译软件 推荐 2026”), German stays German, Turkish stays Turkish.
Same French prompt, three model generations:
Prompt: “Quel est le meilleur logiciel de traduction instantané ?”
+ “best real-time translation software…”
ChatGPT’s localization flipped twice in four months, but it looks like localization will be as important for GEO as it has been for SEO for years, and getting your foreign-language pages to rank well in their own language will only matter more over time.
Which Search Engine Do LLM Citations Come From?
To find out, I scraped the Bing and Google results behind every fan-out query, then compared what I found against the citations ChatGPT actually gave back. (The numbers below are from the original GPT-5.2 wave.) Everyone assumes ChatGPT uses Bing, and for the Business tier, that's true. But the Plus tier tells a different story.
| GPT-5.2 Business | GPT-5.2 Plus | Gemini | |
| Total Cited Links | 1,637 | 1,839 | 1,651 |
| Total Additional Links | 2,820 | 4,506 | — |
| Bing Overlap (Cited) | 81.3% | 67.6% | — |
| Bing Overlap (Additional) | 86.3% | 56.3% | — |
| Google Overlap (Cited) | 27.8% | 64.6% | 77.7% |
| Google Overlap (Additional) | 20.7% | 52.1% | — |
| Total Coverage | 83.7% | 80.6% | 77.7% |
| Invisible (neither index) | 16.3% | 19.4% | 22.3% |
Coverage = Bing ∪ Google for ChatGPT tiers; Google only for Gemini.
Is ChatGPT Scraping Google Search Results?
What raised the question for me, back in the GPT-5.2 study, was the overlap gap between the tiers. Seeing Google overlap jump from 27.8% on Business to 64.6% on Plus, same prompts and same model, was incredibly odd to me.
People in the community had been speculating about this for a while, before I even started the study. While I was doing my early research, I heard Mark Williams-Cook put it plainly in a recent talk: "we know ChatGPT does use Google… they scrape Google or use services to do that to get results." And then I read The Information's piece that OpenAI was using SerpApi, a third-party search-scraping service, to get at Google's results for ChatGPT, after it tried to strike a direct search deal with Google, got turned down. Then in December 2025 Google sued SerpApi over the scraping. Now the story was making more sense to me. But I didn’t expect to see it this clearly in the data, and especially tied this strictly to the subscription tier.
OpenAI’s own docs also hint at the split. For workspace tiers they name Bing as the search provider. The consumer tier docs are vaguer, mentioning that they can use “third-party search providers”, plural and unnamed.
GPT-5.5 Labels the Source Itself
On the GPT-5.5 results, I realized every cited link now also carries a result_source field, naming the provider that returned it. Business search citations are 95% bing; Plus search citations are 94% bright. I suppose this is Bright Data, whose core product scrapes Google. A small share of Plus citations are labeled serp, just 15 references against bright’s 1,012 (about 1.5%). My standing theory is that serp is just a fallback to Bright Data. Now the theory is no longer just an inference. It's written into the response: Business reads Bing, Plus reads a third-party Google scraper.
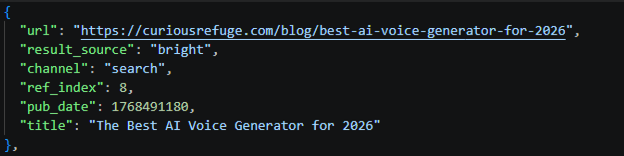
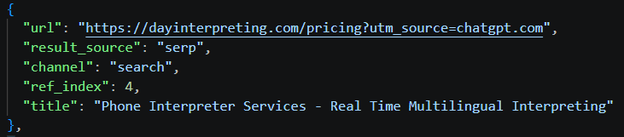
One thing the labels settle: zero of Plus's citations are labeled bing. So the 67.6% Bing overlap I measured back in the GPT-5.2 wave wasn't Plus reading Bing, it was just pages that rank on both engines. It isn't absurd to say GPT Plus's results are essentially Google search results, pulled in through Bright Data and SerpApi.
How Much Does Search Rank Decide Whether You Get Cited?
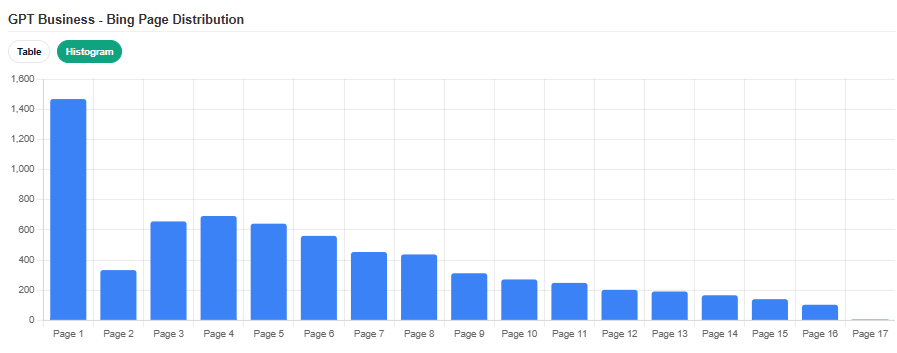
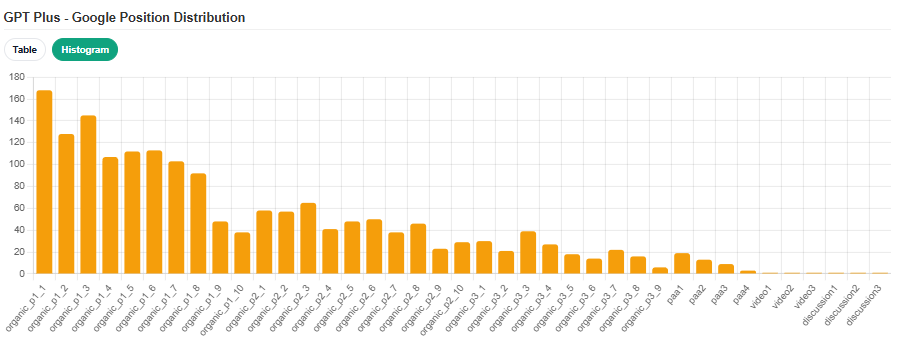
To see how much rank matters, I plotted where the cited + additional links fell in the search results:
GPT-5.2 Business on Bing
GPT-5.2 Plus on Google
Gemini on Google
If your product ranks well on Google but has no Bing presence, you're invisible to ChatGPT Business and Enterprise users. Most companies completely ignore Bing SEO. My data suggests that's leaving a significant chunk of AI visibility on the table, especially for B2B companies whose customers are on enterprise ChatGPT tiers.
What ref_index Reveals: the Rank ChatGPT Actually Saw (GPT-5.5)
Every cited link in the 5.5 payload also carries a ref_index. My guess was that it's the position the search engine returned the result at, so I checked it against my own Bing scrape on the Business runs, and it holds: a Spearman correlation of 0.79 at top-10 depth, with ref_index 1 usually landing at my Bing rank 1. So this is almost certainly the ranking. The rank ChatGPT actually saw, read straight from its own response, no scraping needed.
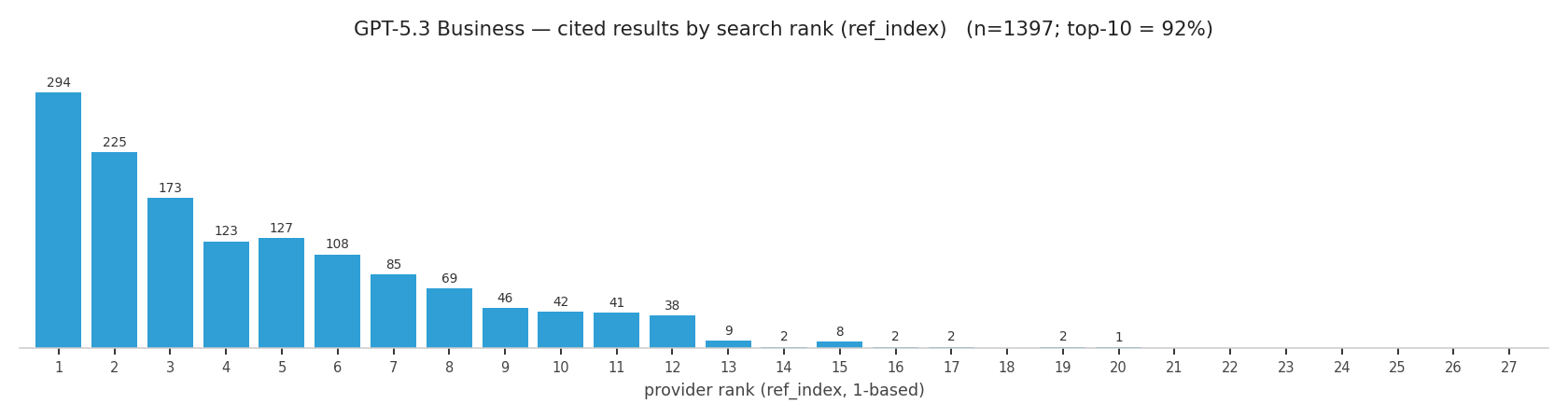
The Ground-Truth Rank Distribution, From ref_index
Okay. Now we can look at the rank distribution from the data ChatGPT hands us, not my scraped approximation.
GPT-5.3 Business
GPT-5.3 Plus
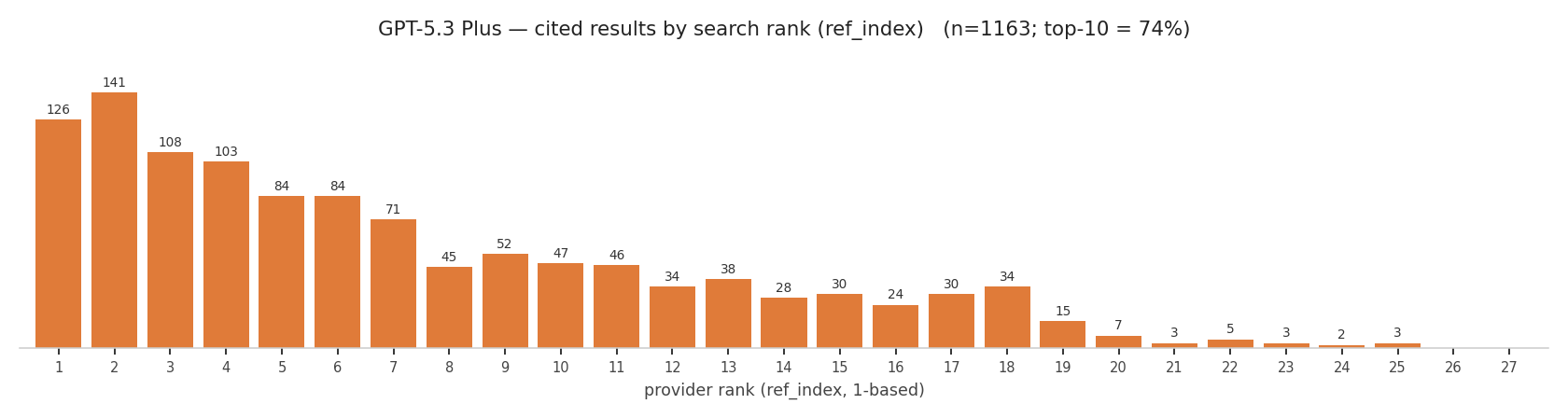
On GPT-5.5, Business almost seems to cite strictly from the top 10, while Plus looks a little deeper, up to around rank 25. Plus's top-5 rates are also flat: ranks 1 and 2 don't get the strong priority over 3-5 that you see in human click-through, or on Business.
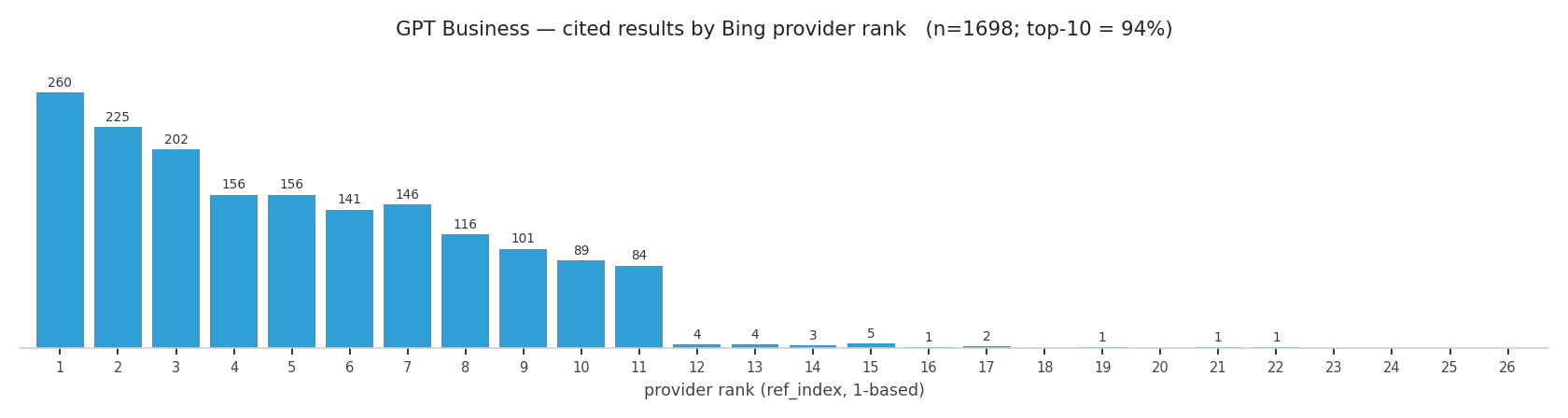
GPT-5.5 Business / Bing
GPT-5.5 Plus / Bright (Google)
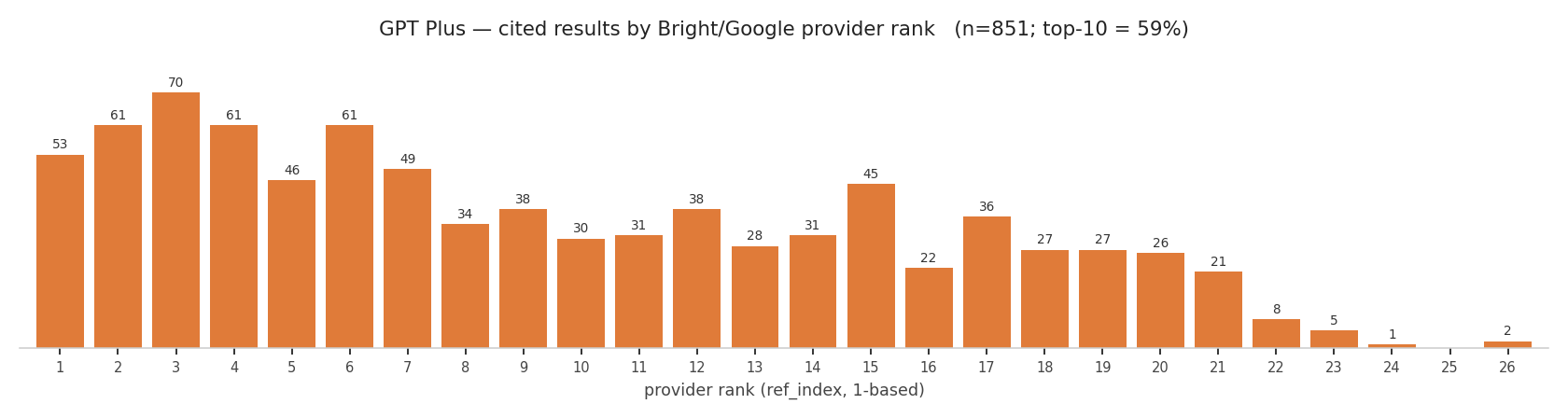
The GPT-5.5 charts look much the same, and the Google/Bright side on Plus is, if anything, even flatter.
On Business, 94% of cited results sit in the top 10 and 99% within rank 12, with only a thin tail out to 22. Plus cites from a deeper, flatter distribution: only 59% in the top 10, reaching into the low 20s. Same model, same prompts; the difference is entirely the provider behind the tier.
That is the practical part. On Business (Bing) you effectively need a top-10 spot to get cited, and most citations come from the top 5. On Plus (Google) there's more room.
The Citations That Bypass Search: Labrador
When I ran the GPT-5.2 study, 16–22% of the cited links (depending on tier) I simply couldn't find anywhere in the Bing or Google results for the same fan-out queries. I called these the invisible links at the time. They were mostly high-authority pages. Wikipedia, arXiv, and big tech-news and editorial sites like The Verge and Wired. I was convinced these weren't coming from regular web search, maybe a separate search over specific sources, or possibly an internal directory of some kind.
Top Invisible Domains
| Domain | GPT-5.2 Business | GPT-5.2 Plus |
| en.wikipedia.org | 109 | 87 |
| arxiv.org | 83 | 69 |
| theverge.com | 51 | 47 |
| sfgate.com | 46 | 42 |
| reddit.com | — | 44 |
| wired.com | 32 | 40 |
| lifewire.com | 34 | 28 |
| time.com | 34 | — |
| timesofindia.indiatimes.com | 32 | 27 |
| techradar.com | 15 | 14 |
| medium.com | — | 13 |
You can browse the full list in the data viewer, with some page types excluded.
GPT-5.5 exposes a source name: labrador
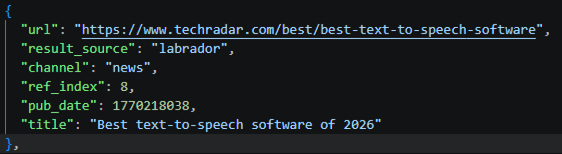
Most result_source values are bing or bright, but a significant chunk are tagged labrador. I assume that's some OpenAI-internal source or index, which is what I earlier called the invisible links. Here are the domains it tags labrador (citations per tier, same counting as the table above):
| Domain | GPT-5.5 Business | GPT-5.5 Plus |
| techradar.com | 33 | 21 |
| en.wikipedia.org | 30 | 14 |
| arxiv.org | 18 | 6 |
| androidcentral.com | 16 | 11 |
| theverge.com | 14 | 10 |
| tomsguide.com | 6 | 16 |
| windowscentral.com | 7 | 5 |
| timesofindia.indiatimes.com | 8 | 3 |
| wired.com | 5 | 1 |
| axios.com | 5 | — |
| nypost.com | 2 | 2 |
Same shape as the GPT-5.2 invisible set, Wikipedia, arXiv, and tech/general press, except now it isn't a guess: the model labels them labrador outright.
What Type of Content Gets Cited?
I extracted the contents of every cited page and had two separate LLMs (GPT-5-mini and Gemini 2.5 Flash) classify each page’s type, the same way on every wave, cross-validated at 88–95% agreement. This was the breakdown:
| Page Type | GPT-5.2 Bus | GPT-5.3 Bus | GPT-5.5 Bus | GPT-5.2 Plus | GPT-5.3 Plus | GPT-5.5 Plus | Gemini |
| Listicle | 27.6% | 45.3% | 60.1% | 17.3% | 46.1% | 48.2% | 53.7% |
| Product page | 48.2% | 34.3% | 11.4% | 52.8% | 28.2% | 19.2% | 19.6% |
| Editorial / News | 6.8% | 5.9% | 11.3% | 4.4% | 6.9% | 12.0% | 4.2% |
| Reference / Docs | 7.7% | 5.7% | 6.1% | 5.9% | 5.3% | 4.3% | 2.0% |
| App store | 5.1% | 5.3% | 2.2% | 14.0% | 7.3% | 5.3% | 1.9% |
The big shift here is the increase in listicle percentage. I attribute it to the year-token injection getting more common with each version (5% of runs in January, 78% by May): year-tagged queries pull "best of 2026" roundups. Product page share falls as the SERP for a "best video to text tool 2026" style fan-out doesn't surface many vendor product pages, so as those queries take over there are fewer product pages left to cite. Some of this is the web shifting underneath the study too: more year-tagged listicles simply existed by May than in January.
The editorial/news row also climbs on both tiers. Those pages come almost entirely through the labrador channel we established (the Wikipedia, arXiv, and tech-press set). The table also shows a sharp tier split on app stores: Plus cites them far more than Business. I think this might be because Google ranks App Store and Chrome Web Store listings prominently while Bing tends to bury them.
Should You Put Your Own Product at #1 in a Listicle?
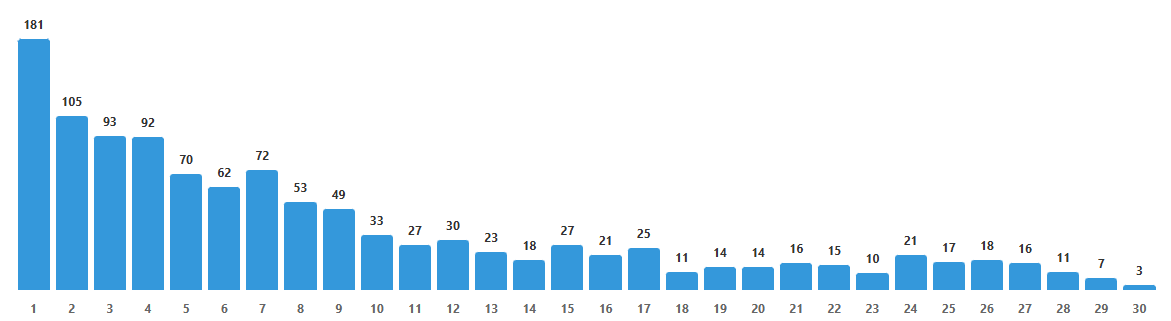
When I ran the GPT-5.2 study, I also looked at where inside a listicle the model actually picks from. Most of these "best tools" listicles are really marketing, written by a vendor that conveniently ranks its own product first. So I wanted to test two things: does position on the list decide what the model picks, and does that self-promotion actually work? Here is how often the model selected each rank, against what you would expect by chance on a typical 8–10 item list:
| #1 Item | Top 3 | Top 5 | |
| Expected by chance (8–10 item list) | ~11% | ~33% | ~56% |
| GPT-5.2 Business | 18.9% | 50.9% | 76.0% |
| GPT-5.2 Plus | 31.7% | 60.5% | 81.0% |
| Gemini | 34.8% | 61.1% | 79.5% |
The #1 item on a listicle is selected at 1.7–2.5x the rate you'd expect by chance. The top 5 items account for 76–81% of all selections, even though the average listicle has 8–10 items. If your product is listed at position 7 or lower, the LLM probably won't even mention it.
When a listicle includes its own host's product, the model picks it about 3.4x more than chance (GPT; 2.3x for Gemini). But almost all of that is the #1 effect: vendors put their own product at the top in 93% of cases, and the top spot is over-selected anyway. Controlling for position, the host gets only a +4.7pp edge over a non-host product in the same #1 slot (which could be explained by the more flattering language a vendor uses about itself). So GPT doesn't penalize self-promoting domains. Does self-promotion work, then? Yes, as long as you can get the listicle to rank in search and place your own product at #1.
After completing this study, I came across Peec AI's Self-promotional listicles analysis: Data from 232,000 citations, which corroborates these patterns at a much larger scale.
Does Structured Content Like Tables or Bullet Points Help You Get Cited?
For the original GPT-5.2 wave I also looked one level deeper: holding page type constant, do cited pages carry more structure (tables, lists, freshness) than the average page in the SERP pool? Short answer: yes, modestly.
Listicles
Across almost all conditions, cited listicles had more structured content features than the average listicle in the SERP pool:
| Feature | Business/Bing | Plus/Bing | Plus/Google | Gemini/Google |
| Tables | +11.4pp** | +3.8pp | +19.7pp*** | +7.8pp** |
| Numbered Lists | +10.3pp*** | +11.2pp* | +9.7pp* | +7.1pp** |
| Bullet Points | +3.4pp | +14.0pp* | +9.7pp* | +4.5pp |
| Freshness | -0.8pp | +16.6pp*** | +9.4pp*** | -0.1pp |
*p<0.05, **p<0.01, ***p<0.001. Drift = (% in cited) - (% in SERP pool). Cited / not-cited N per column: Business/Bing 242 / 858, Plus/Bing 53 / 959, Plus/Google 160 / 2,100, Gemini/Google 468 / 3,349.
Tables and numbered lists are over-selected across nearly all conditions. Gemini shows no freshness drift because its year-token fan-outs already filter for freshness upstream, so everything is fresh by the time it picks citations.
Structural Drift: Product Pages
| Feature | Business/Bing | Plus/Bing | Plus/Google | Gemini/Google |
| Numbered Lists | +11.4pp*** | -4.6pp | +6.8pp*** | +8.8pp* |
| Bullet Points | +6.0pp | +7.5pp | +7.8pp*** | +1.7pp |
| Tables | +0.6pp | +2.8pp | +3.1pp** | -4.4pp** |
*p<0.05, **p<0.01, ***p<0.001. Drift = (% in cited) - (% in SERP pool). Cited / not-cited N per column: Business/Bing 273 / 1,038, Plus/Bing 180 / 1,065, Plus/Google 728 / 2,938, Gemini/Google 181 / 1,522.
Product pages show flatter drift profiles than listicles. They're structurally more homogeneous, most product pages already have similar formatting, leaving fewer features to differentiate on. Numbered lists are the clearest signal, over-selected in three of four conditions.
I also ran logistic regression to factor rank out of the equation, and the structural features still looked like they raise citation likelihood on their own.
If an LLM Cites You, Does It Get the Details Right?
Knowing which pages get cited is one thing. But does ChatGPT accurately reproduce what those pages say, or does it just grab a URL and make things up?
To test this, I needed to map each product claim back to its source. Unlike Gemini, which natively provides segment-level attribution through its grounding API, ChatGPT exposes no such mapping. So I built a pipeline that reconstructs it using the citation tokens hidden in ChatGPT's network responses.
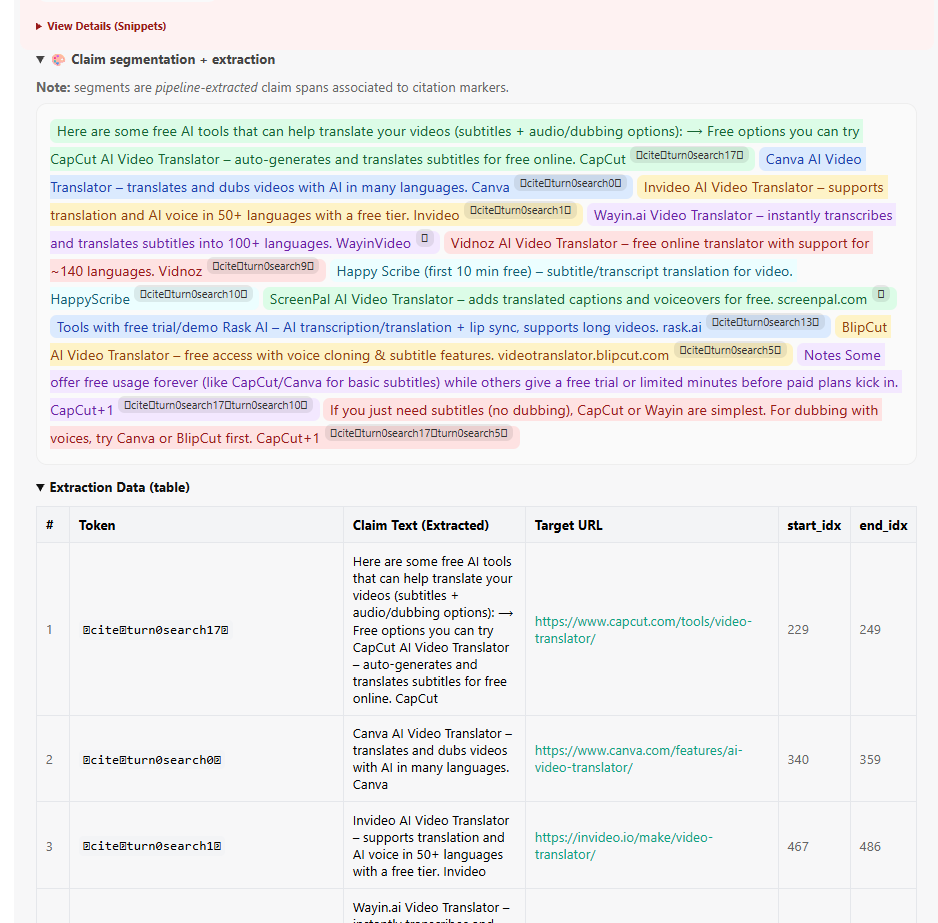
Using an LLM-as-judge approach (GPT-5-mini and Gemini 2.5 Flash scoring independently, cross-validated at 93.9% agreement), I evaluated over 1,110 solo-cited product claims:
- Fidelity score: 4.71/5.0 for GPT, 4.81/5.0 for Gemini. When the product is present in the source, both models reproduce its details with high accuracy.
In short: when a model answers from a real cited source, it gets the details right. This is probably the biggest benefit of retrieval-augmented generation, a model grounded in actual pages is far less likely to hallucinate than one answering from memory. For brands, that means if your product is described on a page that ranks well, ChatGPT will likely represent it accurately. The risk isn't misrepresentation, it's not being cited at all.
Your GEO Strategy Depends on Which ChatGPT Tier Your Customers Are On
What I didn't expect, back in the GPT-5.2 study, was how differently ChatGPT Plus and Business behaved. They run on the same model, use the same classifier, and receive the same prompts, but produced significantly different results.
Search Behavior Differences
Even at the search trigger level, the tiers diverge. Some prompts triggered web search on one tier but not the other.
Here's how often each tier actually triggered a web search, by version. The gap widened as the models updated, with Plus dropping sharply on GPT-5.5:
| Version | Business | Plus |
| GPT-5.2 (Jan) | 91% | 87% |
| GPT-5.3 (Apr) | 91% | 85% |
| GPT-5.5 (May) | 91% | 54% |
Most of that Plus drop is routing, not the model deciding to stop searching: on GPT-5.5, ChatGPT silently sent about a third of Plus runs to a smaller gpt-5-3-mini model, and those runs seem to search far less often.
Source Differences
Beyond the Bing/Google split, the tiers draw from different pools even among invisible citations:
- App stores showed up far more on Plus.
- Reddit, Medium, and community content appeared way more frequently on Plus.
- News and tech-editorial (The Verge and Wired) were cited inline more often on Business.
And regardless of tier, there's one slice you can't win by ranking at all. The labrador first-party channel (~12-15% of citations: Wikipedia, major tech press, arXiv). You don't get into that by climbing a SERP; you get in by being on Wikipedia, earning real editorial coverage, or publishing research. It's the one part of AI visibility that SEO doesn't reach.
How I Collected the Search Data
To check where ChatGPT's citations come from, I captured what Bing and Google return for the same queries, which turned out to be the hard part. Bing retired its search API in August 2025, so I scraped its consumer UI through a US proxy, down to rank 200. I noticed enough quirks in Bing's consumer search interface that I could write a separate blog post on it, so treat the Bing results here as a proxy for what ChatGPT is probably pulling from them rather than an exact copy. For Google, I used SerpApi.
So Is SEO Dead?
When it comes to SaaS product recommendations, absolutely not.
Around 80% of LLM recommendations in the study came directly from search rankings. A page has to rank, and has to rank high, to be cited. And the things that seem to move the needle, structured content like tables and numbered lists, or even putting the current year in your titles, were standard SEO practice years before LLMs showed up. The models rewarding the same features reinforces the existing optimization loop rather than creating a new one.
Honestly, I kind of share Google’s position here. Generative AI search is rooted in the same core ranking mechanics as regular search. There can be short-term fluctuations you can ride with a few GEO hacks, and some understanding of the mechanics is genuinely useful, but I really feel like doing good SEO should earn you AI visibility in the long run.
And the reason I think that bet holds up is that AI search keeps trending toward more retrieval, not less. Here's why:
- Search-grounded answers hallucinate less. When a model answers from actual web sources instead of training data, it's far less likely to make things up.
- Retrieval is cheaper than inference. It's more efficient to query a search index than to scale up model parameters to store all world knowledge. LLM providers probably have enough trouble with their inference costs as it is. The economics favor offloading knowledge to search long term.
- Freshness can't be trained in. No model can retrain hourly to keep up with changing prices, product launches, and reviews. A search index can be queried in real time.
- Training data doesn't have live links. Good luck recommending a SaaS tool without a working URL.
So if these trends hold, search only gets more central to how AI answers product questions, not less, and the way you earn a spot in those answers is still, at its core, good SEO.
You can explore the full dataset at geo.maestra.ai: every run, its fan-out queries, the citations, the Bing and Google results scraped for each fan-out, and the overlap between them. (First load is slow; it's scale-to-zero, so give it a moment to wake up.)
If you have any questions or insights about the study, or just want to talk GEO, hit me up on LinkedIn.
Frequently Asked Questions
Is SEO dead because of ChatGPT and Gemini?
No. About 80% of the AI product recommendations in this study traced directly back to search rankings — a page still has to rank, and rank high, to get cited.
Does ChatGPT use Bing or Google?
Both, split by subscription tier. ChatGPT Business reads Bing (95% of its search citations are labeled bing); ChatGPT Plus reads Google through a third-party scraper, Bright Data (94%). On GPT-5.5 the model labels the provider on every citation in a result_source field.
What ranking position do you need to get cited?
On Business (Bing), 94% of citations come from the top 10 — you effectively need a top-10 spot. On Plus (Google) the distribution is flatter, reaching into the low 20s, so there is a bit more room.
Do “best of” listicles actually work?
Yes, strongly. The #1 item on a listicle is picked at 1.7–2.5x the rate you'd expect by chance, and the top 5 items account for 76–81% of all selections. Below position 7, the model usually won't mention you.
Does putting your own product at #1 in a listicle work?
Yes — as long as the listicle ranks in search and you place your product at the top. The model doesn't penalize self-promoting domains; a host's own product gets picked about 3.4x more than chance, mostly because vendors put themselves at #1 and that slot is over-selected anyway.
What is the “labrador” channel?
An internal, first-party source GPT-5.5 labels labrador — roughly 12–15% of citations, drawn from Wikipedia, arXiv, and major tech press. These don't come from web ranking, so it's the one part of AI visibility that SEO can't directly reach.
